Kafka Consumer Configuration: Optimize Performance with Key Settings & Use Cases
Kafka Consumer Configuration is at the heart of building efficient, scalable, and reliable data streaming applications. Whether you’re working with event-driven architectures, batch data ingestion, or real-time stream processing, the right configurations can make all the difference. In this guide, we’ll explore the most important Kafka consumer settings, break down their impact, and showcase practical use cases to help you optimize performance. By the end, you’ll have a clear roadmap to fine-tune your Kafka consumers for maximum efficiency.

On this page
Apache Kafka is a distributed streaming platform designed to develop real-time data pipelines and streaming applications. It boasts high throughput and low latency and can process millions of messages per second. Kafka is frequently utilized as a message broker, facilitating communication among various software systems through message production and consumption.
This article will concentrate on the configuration of Kafka consumers. It is imperative to properly configure and manage consumers to ensure the efficient and reliable processing of messages. We will examine critical configuration parameters, provide guidance for optimizing consumer performance while avoiding common pitfalls, and outline best practices in security and engineering.
Summary of key Kafka consumer configurations
You can explore countless configurations for a Kafka consumer, yet the default values are often sufficient for most scenarios. Remember to focus on a few key settings you’ll want to ensure are perfectly tuned.
Configuring a Kafka consumer
Get ready to dive into the world of Kafka client libraries, which are available in almost every major programming language! While you might encounter some unique syntactical twists depending on the language, the overall process remains thrillingly consistent. One of the best practices that developers like is using a config file to set the configuration properties, as it offers clarity and ease – especially since these properties are in dot notation and can’t be used as environment variable names. So, let's make your Kafka experience seamless and efficient!
Here’s an example configuration file:
# Filename: kafka-consumer.properties
# Connection settings
bootstrap.servers=192.168.1.50:9092,192.168.1.51:9092
security.protocol=SSL
ssl.truststore.location=/path/to/truststore.jks
ssl.truststore.password=truststore-password
ssl.keystore.location=/path/to/keystore.jks
ssl.keystore.password=keystore-password
ssl.key.password=key-password
# Consumer settings
enable.auto.commit=true
auto.commit.interval.ms=5000
auto.offset.reset=latest
heartbeat.interval.ms=3000
max.poll.records=100
max.poll.interval.ms=300000
session.timeout.ms=30000
# Consumer group settings
group.id=my-consumer-group
group.min.session.timeout.ms=6000
group.max.session.timeout.ms=30000
Using that config file to create a Kafka consumer with the Java client library will result in a powerful and efficient setup. Which can look like this:
Properties props = new Properties();
try {
props.load(new FileInputStream("kafka-consumer.properties"));
} catch (IOException e) {
// Handle exception
}
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
Here’s an example using Python:
import configparser
config = configparser.ConfigParser()
config.read('kafka-consumer.properties')
props = {
'bootstrap.servers': config.get('consumer', 'bootstrap.servers'),
'group.id': config.get('consumer', 'group.id'),
'auto.offset.reset': config.get('consumer', 'auto.offset.reset'),
'max.poll.records': int(config.get('consumer', 'max.poll.records'))
}
consumer = KafkaConsumer(props)
Essential Kafka Consumer Configurations - to let you start in the right way
max.poll.records
This setting determines how many messages a consumer fetches in a single call to poll().
- Higher values improve throughput but may lead to duplicate processing in case of failures.
- Lower values reduce duplication risks but may slow processing.
Fine-tuning this ensures efficient message handling and a good balance between speed and reliability.
group.id
The group.id uniquely identifies a consumer group and tracks its position in a topic. When a consumer starts, it looks up its group.id to determine where to begin reading.
Consumers within the same group share offsets and can seamlessly resume processing after failures. It’s important to assign a unique group.id to each group to prevent conflicts with other consumers.
enable.auto.commit
This configuration decides whether offsets are committed automatically.
- When enabled (true), offsets are committed at regular intervals, ideal for straightforward message consumption.
- When disabled (false), offsets must be committed manually using commitSync(), which is better for cases requiring additional message processing, like storing data or forwarding messages.
Choosing the right setting depends on whether messages require further handling before being marked as processed.
heartbeat.interval.ms
This setting controls how often a consumer sends heartbeats to the Kafka broker to confirm it’s still active.
If a consumer fails to send heartbeats within this interval, the broker assumes it has crashed and triggers a rebalance. Shorter intervals allow for faster failure detection but increase processing overhead, while longer intervals reduce load but delay failure response.
auto.offset.reset
This option defines where a consumer starts reading if there are no existing offsets or if the last offset is unreachable.
- "latest" – Begins consuming from the most recent message.
- "earliest" – Starts from the oldest available message.
Setting this correctly ensures predictable consumer behavior, especially when adding new consumers or recovering from failures.
bootstrap.servers
This is a list of host:port pairs that the Kafka client uses to connect to the Kafka cluster. For resilience and failover support, it’s best to specify at least two brokers.
max.poll.interval.ms
This defines the longest time a consumer can go without polling Kafka before being marked as failed.
- If the interval is too short, consumers that require more time for processing may trigger unnecessary rebalances.
- If it’s too long, message latency may increase.
Tuning this setting ensures consumers stay active without causing unwanted disruptions.
Use it like a pro - Common use cases
Having discussed the theoretical aspects of different configurations, let’s now examine some typical scenarios where configurations may hold significant importance.
Load-Balancing Across Consumer Groups
In high-throughput systems, multiple consumer groups often process different subsets of data from the same topic. Properly tuning group.id ensures that each group operates independently, preventing message duplication while maximizing resource utilization. Additionally, setting max.poll.records appropriately helps balance workload distribution, preventing some consumers from being overloaded while others remain underutilized.
Event-driven architectures
In an event-driven architecture, the consumers are microservices that must be highly responsive to each individual event. If these consumers are started while there is already a backlog in the Kafka topic, it might take some time for them to process the more recent events, and this lag could propagate through the system. To ensure that consumers can quickly handle new messages right after startup, you might want to set auto.offset.reset to “latest.” On the other hand, if your intention is to process the complete event log, even for events that were generated while the consumers were offline, you must ensure that this setting is configured to “earliest.”
Fault-Tolerant Message Processing
When reliability is critical, ensuring consumers can recover from failures without data loss is key. By disabling enable.auto.commit, you can control exactly when offsets are committed, ensuring messages are only marked as processed after successful handling. This approach prevents data from being skipped or reprocessed unnecessarily in the event of a crash. Configuring auto.offset.reset to "earliest" ensures no messages are lost when new consumers come online after downtime.
Real-time stream processing
In situations where your system requires immediate insights or actions based on streaming data, lowering the heartbeat.interval.ms value leads to quicker responsiveness from consumers and allows for the swift identification of unhealthy consumers. Furthermore, increasing the number of partitions in the topic will help scale the consumer capacity significantly to prevent the accumulation of lag and latency.
Optimizing Consumer Scaling in Kafka
Once your consumers are running, the next challenge is finding the right balance with producers. Scaling up consumers may seem like the solution when they fall behind, but beyond a point, it won’t help.
Kafka distributes messages across partitions, each assigned to a consumer within a group. If there are more consumers than partitions, the extras sit idle, wasting resources. To scale effectively, ensure the number of consumers aligns with partitions or increase partitions as needed. A well-balanced setup maximizes throughput and enables seamless real-time processing.
Plan ahead, optimize smartly, and scale efficiently!
Kafka Consumer Configuration Example
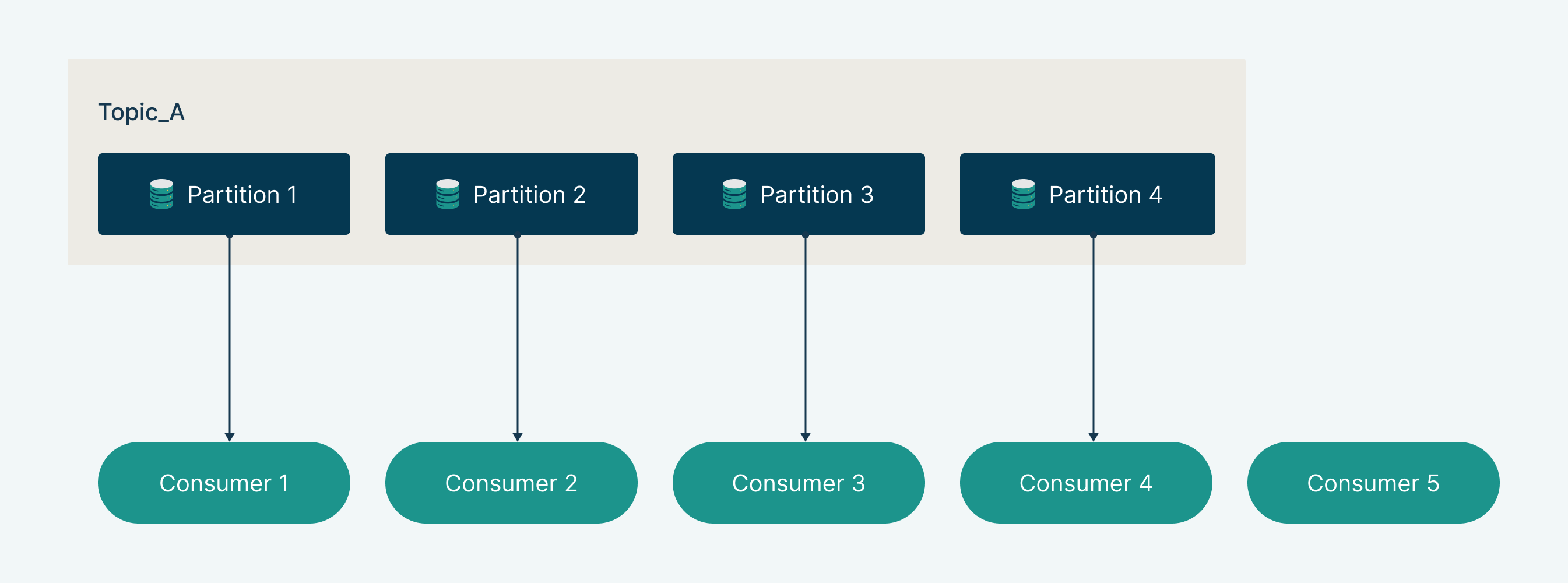
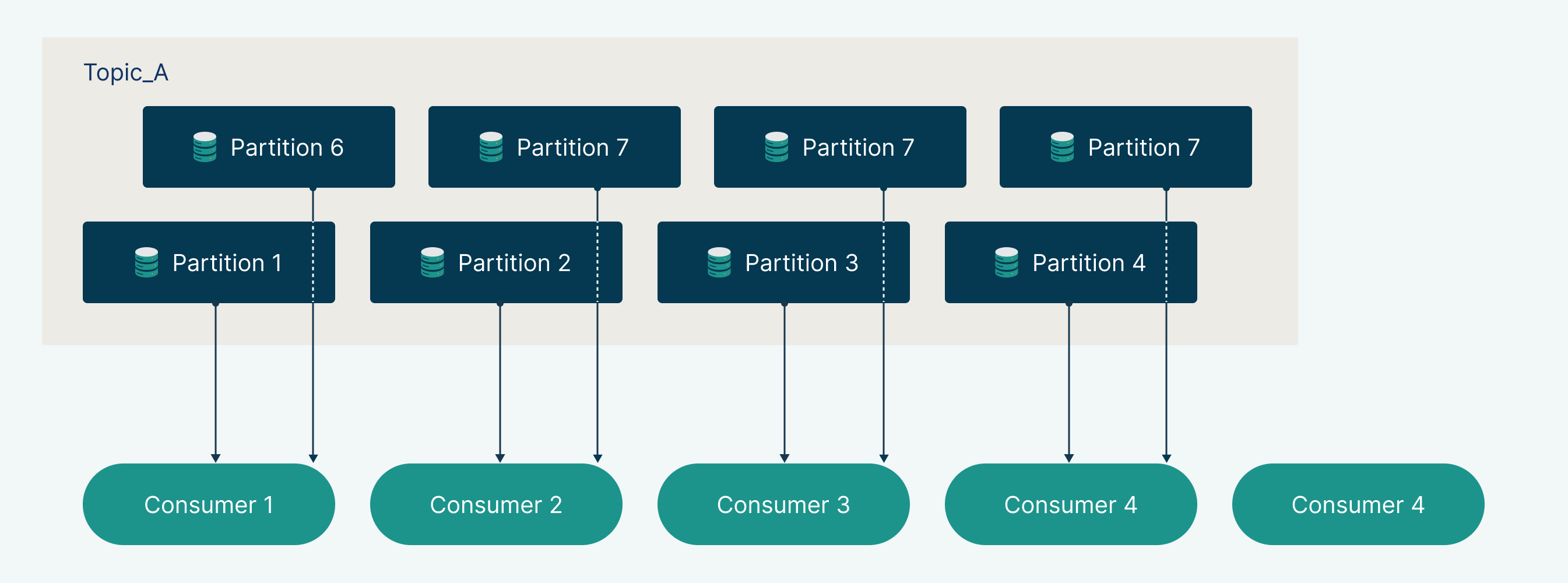
Conclusion
To set up a Kafka consumer, you need to adjust some important settings. These settings control how the consumer behaves and performs. They specify the consumer group it belongs to, whether it will automatically save its progress, and how it will start when the starting point is unknown. They also determine how often the consumer sends heartbeats to the group coordinator and the maximum number of records it will retrieve in one go.
At Axual, we understand the complexities of managing Kafka consumers at scale. Our platform simplifies the management of Kafka clusters, providing powerful tools to monitor, configure, and scale your consumers without the hassle. Whether you're managing consumer groups, adjusting offsets, or ensuring the health of your Kafka ecosystem, Axual’s intuitive interface and robust automation help you navigate Kafka's intricacies with ease. Let us handle the complexities of Kafka management so you can focus on driving value from your real-time data streams.
We trust that this guide has effectively outlined the key concepts and considerations for setting up and utilizing Kafka consumers, helping you to navigate the process with greater clarity and confidence. Good luck on your adventure in mastering your Kafka consumers.

Answers to your questions about Axual’s All-in-one Kafka Platform
Are you curious about our All-in-one Kafka platform? Dive into our FAQs
for all the details you need, and find the answers to your burning questions.
To configure a Kafka consumer, define properties like bootstrap.servers (Kafka broker addresses), group.id (unique consumer group identifier), and auto.offset.reset (earliest or latest for offset handling). Adjust enable.auto.commit for automatic or manual offset commits. Tune max.poll.records and heartbeat.interval.ms for performance. Use a Kafka consumer client (Java, Python, etc.), subscribe to topics, and call poll() to fetch messages.
Kafka configuration refers to the set of properties that control broker, producer, and consumer behavior. Key consumer settings include group.id, auto.offset.reset, enable.auto.commit, and max.poll.records. Broker settings define replication, partitions, and retention, while producer settings control batching and retries. Proper tuning ensures optimal performance, fault tolerance, and scalability.
A Kafka consumer subscribes to topics, retrieves messages via poll(), and processes them. Consumers in the same group.id share topic partitions, ensuring parallel processing. Offsets track progress, either committed automatically (enable.auto.commit=true) or manually. If a consumer fails, Kafka reassigns its partitions to active consumers, maintaining fault tolerance.
Related blogs

Axual 2026.2, the Summer LTS release, brings continuous message fetching and CEL-based queries to Topic Browse, Externalised Groups for managing membership through your Identity Provider, the move to Apicurio v3, improved Audit Events, KSML 1.3, and new MCP Server capabilities.

A technical overview of the Strimzi 1.0.0 CRD migration path, including CRD versioning, conversion tooling, storage updates, and operational considerations for ArgoCD-managed GitOps Kubernetes environments.
.png)
This blog explores why many European organizations and policymakers remain skeptical of AWS’s “sovereign” cloud initiative. From concerns around US jurisdiction and the CLOUD Act to questions about operational independence, data governance, and true digital sovereignty, we break down the key reasons behind Europe’s hesitation. The article also examines the broader push for European cloud alternatives and what this means for enterprises navigating compliance, security, and infrastructure strategy.